ReCAPTCHA was a small project started in 2007 by a small team at Carnegie Mellon University. The concept was, and remains, very simple. Use humans to solve small puzzles which are easy for us and hard for machines to do. It didn’t take Google all that long to see the potential though and it was acquired by them in 2009.
Originally ReCAPTCHA was working with the Gutenburg project in order to help decipher text which couldn’t be automatically scanned. At the time Google was battling this exact problem as part of their Google books project. So it was a natural move to acquire ReCAPTCHA and use their technology.
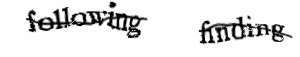
Each set of text is scanned by two different OCR programs. The results are matched against each other as well as the Oxford English dictionary. Where there is a discrepancy the word is marked as suspicious and will then be used in a CAPTCHA.
At this point the system doesn’t know what the word is. This doesn’t really help prevent bots as they could enter any approximate text and the system would accept it, having no reference. So a control word is also needed. One known to the system but which cannot be guessed by a bot.
To solve this the control word is one that both OCR programs have failed to recognize and which was solved by humans. This means a spammer would need access to OCR software better than the state of the art programs reCAPTCHA are using, to be in with a shot.
It also takes surprisingly few solves for a word to be treated as valid. Half a point is assigned to the OCR programs interpretation and a full point for each human solve. It takes just 2.5 points for a word to be counted as valid. So if one of the OCR programs and two humans agree, then it’s counted as solved.
The no CAPTCA reCAPTCHA
The next evolution from the typed capture is the ‘I am not a robot’ click we’re all familiar with. Here Google did away with getting us having to actually write something and instead just used an analysis of our behavior in making that click to decide if we are human.
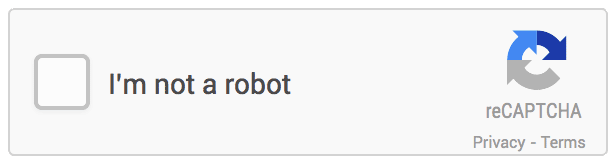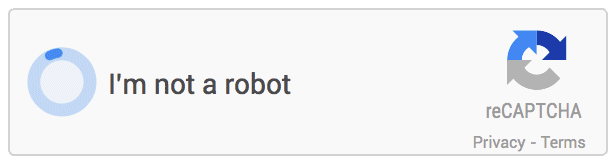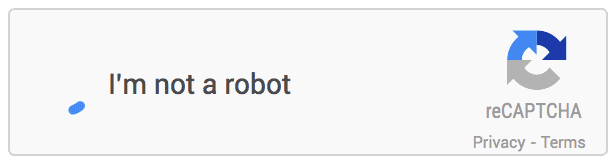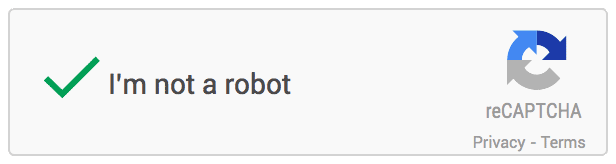
If you fail the click test (It’s never happened to me, but maybe there are some cyborgs out there with hurt feelings) then you are presented with a much harder fallback CAPTHCA. Solve this and you are counted as human and your ‘click behavior’ can be added as a legitimate human click.
Google has seen a lot of criticism for just how inaccessible reCAPTCHA is, with many people remarking on how hard it is to solve for those who use screen readers and other assistive technology. The audio fallback was made available to solve this, but this has had its own security issues.
Google also saw the opportunity to use some free human labor to solve issues outside of the Google Books project. In 2012 Google Street View started using numbers captured from houses within reCAPCHA. This allowed them to more accurately pinpoint locations. So you can put in a street number and get an approximate location.
Have you ever wondered how Google Maps knows the exact location of your neighborhood coffee shop? Or of the hotel you’re staying at next month? Translating a street address to an exact location on a map is harder than it seems
Vinay Shet - PM Google reCAPCHA project
Next Google went on to start including pictures of animals, in 2014. This created a more visual capture and one that was a bit more accessible, as it was a lot easier for humans to solve.

What else was Google working on in 2014? Well from 2012 onward Google was making big steps with image recognition, launching the reverse image search and in 2015 the Cloud Vision API.
The next evolution has been to remove the need to take any more action than a single click. This is by far the most accessible version and requires the user simply to click on a button.
Google has progressed to the point of looking at the behavior of making a click and judging if it’s human just from that. There’s another major area driving 70% of revenue for not just Google but for Alphabet as well, which means that clicks are incredibly important too.
Adwords has been trying to detect click fraud for years and so it makes sense to integrate this into the reCAPTCHA program. Now there is a feedback mechanism as well, for better identifying false positives. With reCAPTCHA a suspicious click can be given a fallback CAPTCHA to definitively prove whether human or robot. This allows them to continuously refine the behavior that makes a click human.
It makes sense that this would feed back into their paid advertising programs, enabling even better detection of fraudulent clicks.
The invisible CAPTCHA
Now Google has taken that leap one step further, no longer even requiring the user to click on a button.
Just from your behavior ‘on page’ Google will be judging if you are a bot or a human. It’s a fair guess that this technology won’t be confined to reCAPTCHA either, based on how they have used it previously to add value to other projects.
So could Google use this to include your behavior in the organic ranking algorithms?
To the best of my knowledge Google does not currently use clicks as a ranking factor (but please add your thoughts on this to the comments). The most recent solid confirmation from Google I have on this are the comments from Gary Illyes at SMX back in 2015.
Gary stated that Google does not use clicks as a ranking factor, interestingly because it would be too noisy. He also stated that they don’t use bounce back to the page either. Some earlier experiments did show a correlation, so it looks like Google may have tried it, saw it was too easily spammed and rolled back on it.
Now Google has a much more effective way of determining if the traffic on page is human or bot it could potentially try this again. It’s something I think would make a big difference and actually make the rankings far more dynamic. It’s also something Google really needs to do as traditional ranking signals such as links become increasingly hard to rely on.
Really, what better measure of a results' usefulness is there than looking at what people click on in relation to its position on page? It seems such an obvious and clear signal that I would be surprised if Google didn’t revisit it when they felt they had more robust protection against people gaming the system in place.
They can at the very least sort out the bots in my Analytics traffic...
Within Google Analytics there has been a constant battle against the bots. The option has been around for a while within your account to filter out ‘known bot traffic’ but as I can personally attest from our own account, this still leaves a lot of bot traffic getting through.
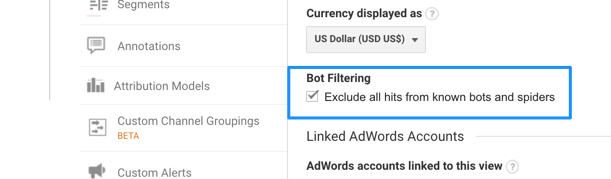
Being able to better, automatically, identify bots could go a long way to making the reported traffic in GA more accurate. If they don’t use it for anything else I might benefit from, they could at least use it for this!
However I'll leave the final word to one of the team of that originally invented reCAPTCHA, when asked to describe the project...
a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles.
Luis von Ahn, early reCAPTCHA developer.
